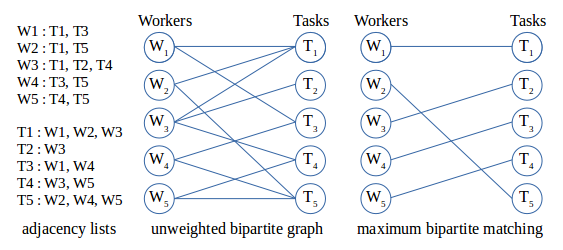
Maximum bipartite matching
Consider a situation where there are many tasks to be done and as many workers available to do them. Every worker has a number of tasks it can do; this may be 0, 1 or more than 1 task. So a task may have 0, 1 or more than 1 available worker who can do it. The challenge is to assign only one task to each worker, and do as many of these assignments as possible. Each assignment is a matching, and a maximum of these is needed. Since it is between two parts (workers and tasks) it is thus bipartite.
In the field of Graph Theory this challenge is modeled as the problem of finding a maximum bipartite matching. The fact that a worker W can do a task T is modeled as an edge (W,T) between two vertexes labeled W and T. Both are said to be adjacent to each other. The collection of all these edges is a graph. Since no associated weight is given to an edge, which would have been the case if for example payment was given for doing a task, the graph is said to be unweighted. Below is an example:
This document presents a new and very efficient algorithm to solve the maximum matching problem for an unweighted bipartite or non-bipartite graph, in O(E log V) time where E and V are respectively the number of edges and vertexes of the graph. It consists of two main parts: a simple vertex get-and-match traversal, followed by an improved backtracking-search for any residual unmatched vertexes.
Contents:
- The common method
- The backtracking search
- The basic idea of the algorithm
- Steps for 1st part of algorithm
- Steps for 2nd part of algorithm
- Algorithm implementation
- Links
- See also
The common method
There is a common method to solve the problem. The Hopcroft-Karp algorithm is essentially an improved version of it. The method is to go through all vertexes one after another, and each time assign/match an unmatched/free adjacent vertex. The easy scenario is when the unmatched next-taken vertex directly has a free adjacent vertex, in which case the two are matched to each other.
Difficulty arises when the next-taken vertex has no free adjacent vertex, in which case a backtracking search is performed. The idea behind this search is to go through vertexes already taken (thus the word backtracking) while checking if any can be matched to a different adjacent vertex, thereby freeing the one it is currently monopolising. This takes O(E) time. For V vertexes a total of O(EV) time is taken.
The backtracking search
The search starts by initialising a queue (or stack) to contain the next-taken vertex.
A vertex u is popped from the queue. u claims for a non-claimed adjacent vertex A0 currently monopolised by a vertex B0, and also claims for another non-claimed adjacent vertex A1 currently monopolised by B1 (and so on for all its adjacent vertexes).
u does this claiming by marking as claimed the vertexes A0 and A1, marking itself as the claimer, then pushing B0 and B1 to the queue. The claiming process is repeated with the next u vertex popped from the queue until the queue is empty or a free vertex, say v, is uncovered. A graph structure that records this traversal is called an augmenting path.
When v is uncovered the information about claimer and claimed vertexes is used to re-match these vertexes. Precisely the final u as the claimer to the uncovered v is matched to this v. But this matching is done only after the vertex currently monopolised by u has been freed and recorded as the next-v. Then the next-u known to be the claimer of next-v is obtained. The re-matching process is thus repeated using this (next-u, next-v) pair, until the initial u is reached.
The search starts with an unmatched u and is guaranteed to uncover a free vertex if any exists. This is because in the worst case scenario, all already matched vertexes will be checked for whether any has a free adjacent vertex. This is true even for a non-bipartite graph where a claimer can become a claimed, though extra care should be taken so to not end up matching the initial u to itself.
The basic idea of the algorithm
Looking at the common method, a key observation can be made which will provide the O(E log V) time, which is that: the next-taken vertex can be the vertex with the minimum number of free adjacent vertexes. This way the chances of it getting matched to the correct vertex is significantly increased. This is the 1st part of the algorithm.
A minimum-heap data structure is used to get hold of this vertex of minimum count of free adjacent vertexes. A binary heap provides O(log V)-time push, pop, remove and update operations. There are O(E) of these, giving a total of O(E log V) execution time.
The 1st part of the algorithm is often enough to solve the problem optimally (actually the condition for which it fails remains unknown). But when it fails an improved backtracking-search is performed to match residual unmatched vertexes - this is the 2nd part of the algorithm.
The backtracking-search is improved in that it starts with all unmatched vertexes so that it may traverse multiple augmenting paths. This is similar to the Hopcroft-Karp algorithm but different in that the augmenting paths traversed are not necessarily shortest. The search is based on breadth-first search and thus uses a queue, not a stack. It is designed to work for any unweighted graph. The re-matching process is directly performed whenever a free vertex is found.
The 2nd part of the algorithm takes O(E) time. It is repeated until no free vertex is found. If it is executed a constant number of times then the overall time complexity of the algorithm is O(E log V) + O(E) = O(E log V). There is no proof of a constant number of executions needed. But this is likely the case due to the significant efficiency of the 1st part of the algorithm. However the 2nd part on its own sometimes performs better than the overall algorithm, taking only O(E) time.
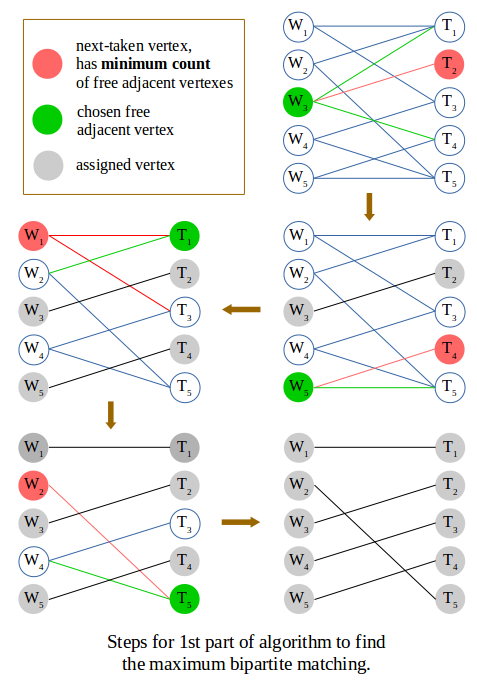
Steps for 1st part of algorithm
- Initialise the heap with all vertexes, based on their count of free adjacent vertexes. Those with no adjacent vertex can be skipped.
- If heap is empty then quit. Otherwise pop a vertex u, referred to as the next-taken vertex. It must have the minimum count of free adjacent vertexes. If this count is 0 then repeat this step 2. Otherwise go to next step.
- Get v, the one of the free adjacent vertexes of u that has the smallest count of free adjacent vertexes, and remove it from the heap. Match the two vertexes u and v to each other, then go to next step.
- For each of u and v, go through its adjacent vertexes still inside the heap, and tell each of them that one adjacent vertex has been monopolised. That is, decrement their count of free adjacent vertexes, then update their position in the heap. Now go to step 2.
Steps for 2nd part of algorithm
... to be updated ...
As may be noticed from the source code below, this section is harder to explain...
Consider donating at https://www.rhyscitlema.com/donate to encourage improvement!
Algorithm implementation
The code below implements the algorithm. The code pieces have been collected from https://github.com/rhyscitlema/algorithms. An example input file is graph.txt (click to download, then read the first few lines).
/*
To compile with GCC, execute:
gcc -Wall -std=c99 -pedantic -o match maximum-bipartite-matching.c
To run, execute: ./match graph.txt
*/
#include <stdio.h>
#include <string.h>
#include <stddef.h>
#include <stdbool.h>
#include <assert.h>
#include <malloc.h>
typedef struct { char* data; long size; } Array;
Array file_to_array (const char* filename, Array old);
typedef long cost; // must match with load_edge_list()
typedef struct { int u, v; cost c; } Edge, *EdgeP;
typedef struct { int v; cost c; } Adge, *Adja, **AdjaP;
typedef const Edge* const_EdgeP;
typedef const Adja* const_AdjaP;
AdjaP load_adja_list (const char* str); // parses and returns adjacency list
char* print_edge_list (char* out, const_EdgeP edge); // returns end of string
EdgeP maximum_matching_unweighted (const_AdjaP adja, bool skipPart1);
int main (int argc, char** argv)
{
if(argc!=2)
printf("Usage: <program> graph.txt\n");
else
{
Array content = {0};
content = file_to_array(argv[1], content);
if(content.size<=0)
printf("Error: failed to open file '%s'.\n", argv[1]);
else
{
AdjaP adjaList = load_adja_list(content.data);
EdgeP edgeList = maximum_matching_unweighted(adjaList, true);
char str[10000];
print_edge_list(str, edgeList);
puts(str);
free(adjaList);
free(edgeList);
}
free(content.data);
}
return 0;
}
/* ... rest of source code ... */
Download the complete C source code
Below is the portion of the source code that implements the algorithm.
typedef struct {
int i; // the free-memory needed by heap.h
int c; // count of free adjacent vertexes
// i must be declared first so to have:
// vertex = (mmug*)heap_node - mmug_array;
} mmug;
/* compare count of free adjacent vertexes */
static int mmug_heap_node_compare (const void* a, const void* b, const void* arg)
{ return ( ((const mmug*)a)->c - ((const mmug*)b)->c ); }
EdgeP maximum_matching_unweighted (const_AdjaP adja, bool skipPart1)
{
if(!adja) return NULL;
int i, m, u, v;
int V = AdjaV(adja); // get V = number of vertexes
const_AdjaP graph, prev = AdjaPrev(adja);
// adja = adjacency list of source-to-sink vertexes
// prev = adjacency list of sink-from-source vertexes
// if adja==prev then graph is an undirected graph
// get m = total memory needed
m = (1+V)*(sizeof(int)+sizeof(mmug)+sizeof(void*));
int* match = (int*)malloc(m);
mmug* count = (mmug*)(match+1+V);
void** hdata = (void**)(count+1+V);
if(match==NULL) return NULL; // if failed to allocate memory
for(u=1; u<=V; u++) match[u]=0; // else initialise main array
//*****************************************************************
//*** Part 1 of algorithm : is often enough to solve optimally! ***
//*****************************************************************
if(!skipPart1) {
// initialise the heap data structure
Heap _heap = { hdata, 0, V, true, NULL, mmug_heap_node_compare };
Heap *heap = &_heap;
// initialise the heap with all vertexes
for(u=1; u<=V; u++)
{
// get m = total number of adjacent vertexes
m = AdjaU(adja,u)[0].v;
if(adja!=prev) // if a directed graph
m += AdjaU(prev,u)[0].v;
count[u].c = m;
if(m) // if at least one adjacent vertex
heap_push(heap, &count[u].i);
}
while(true)
{
void* hnode = heap_pop(heap);
if(hnode==NULL) break; // if heap is empty then quit
// get u = vertex with minimum count of free adjacent vertexes
u = (mmug*)hnode - count;
if(count[u].c==0) continue; // if no free adjacent vertex then skip,
count[u].c=0; // else mark u as removed from the heap.
int t=0;
graph = adja; // start with 'adja' (source-to-sink) list
while(true)
{
Adja U = AdjaU(graph,u);
m = U[0].v; // get number of adjacent vertexes
for(i=1; i<=m; i++) // for every adjacent vertex
{
v = U[i].v; // get adjacent vertex
if(count[v].c>0) // if is inside heap
{
count[v].c--; // decrement count of free adjacent vertexes
heap_update(heap, &count[v].i); // update position in heap
// get free vertex with minimum count of free adjacent vertexes
if(t==0 || count[t].c > count[v].c) t=v;
}
}
if(graph==prev) break;
else graph = prev; // switch to 'prev' (sink-from-source) list
}
v=t; // get v = new free vertex
match[u] = v; // match free vertex
match[v] = u;
count[v].c = 0; // remove v from heap
heap_remove(heap, &count[v].i);
// now tell all adjacent to v that v is monopolised.
u=v; // set u=v so to use exact same code as before!
graph = adja; // start with 'adja' (source-to-sink) list
while(true)
{
Adja U = AdjaU(graph,u);
m = U[0].v; // get number of adjacent vertexes
for(i=1; i<=m; i++) // for every adjacent vertex
{
v = U[i].v; // get adjacent vertex
if(count[v].c>0) // if is inside heap
{
count[v].c--; // decrement count of free adjacent vertexes
heap_update(heap, &count[v].i); // update position in heap
}
}
if(graph==prev) break;
else graph = prev; // switch to 'prev' (sink-from-source) list
}
}
} // end of if(!skipPart1)
//****************************************************************
//*** Part 2 of algorithm : may be faster when executed alone! ***
//****************************************************************
int E; // number of edges of the result graph
while(true)
{
int beg=0, end=0;
int* queue = match+(1+V)*1; // queue used by the breadth-first search.
int* claim = match+(1+V)*2; // claim[v] is the claimer of the claimed v.
int* vfree = match+(1+V)*3; // vfree[v] is the free vertex to start claiming
// initialisations, push all unmatched vertexes to queue
for(u=1; u<=V; u++)
{
if(match[u]) // if u is a matched vertex
{ claim[u] = vfree[u] = 0; }
else { claim[u] = vfree[u] = queue[end++] = u; }
}
// get E = count of matched vertex pairs
E = (V-end)/2;
//printf("-------------------------------------- E=%d\n", E);
for( ; beg!=end; beg++) // do the queue-based backtracking-search
{
u = queue[beg];
v = vfree[u]; // get v = free vertex which u is derived from
assert(v>0);
if(match[v]) continue; // check whether this v is still unmatched
graph = adja; // start with 'adja' (source-to-sink) list
while(true)
{
Adja U = AdjaU(graph,u);
m = U[0].v; // get number of adjacent vertexes
for(i=1; i<=m; i++) // for every adjacent vertex
{
v = U[i].v; // get adjacent vertex
int t = vfree[v]; // get t = free vertex which v is derived from
// check whether a new re-matching has been uncovered
if(t && !match[t] && t != vfree[u])
{
claim[v] = u; // ensure v is never claimed again
int tv = match[v]; // prepare for 2nd re-matching
while(true)
{
claim[u] = u; // ensure u is never claimed again
t = match[u]; // prepare for next iteration
match[u] = v;
match[v] = u; // uncover the augmenting path
if(t==0){
if(tv==0) break; // if no further re-matching
t=tv; tv=0; // prevent any further re-matching
}
v = t; // get v = the next claimed vertex
u = claim[t]; // get u = the claimer to this v
}
E=-1; // notify that a re-matching process was performed
break;
}
if(!claim[v]) // if not yet claimed
{
claim[v] = u; // Mark u as claiming v
t = match[v]; // Get who monopolises v
vfree[t] = vfree[u];
queue[end++] = t; // Push it to queue
}
}
if(i<=m) break; // if re-matching was performed then break
if(graph==prev) break;
else graph = prev; // switch to 'prev' (sink-from-source) list
}
}
if(E!=-1) break; // no re-matching performed means solution is optimal
}
// allocate memory for the result graph
EdgeP edge = (EdgeP) malloc ((1+E)*sizeof(Edge));
// build the edge-list of the result graph
for(E=0, u=1; u<=V; u++)
{
v = match[u];
if(v<u) continue; // avoid repetitions
++E;
edge[E].u = u;
edge[E].v = v;
edge[E].c = 1; // set weight to = 1
}
edge[0].u = V;
edge[0].v = E;
edge[0].c = 0; // mark as undirected
// free allocated memory
free(match);
return edge;
}
Links
- https://en.wikipedia.org/wiki/Matching_(graph_theory)
- https://en.wikipedia.org/wiki/Bipartite_graph
- https://en.wikipedia.org/wiki/Time_complexity
- https://en.wikipedia.org/wiki/Hopcroft–Karp_algorithm
- https://en.wikipedia.org/wiki/Binary_heap
- https://en.wikipedia.org/wiki/Breadth-first_search
See also